Spark는 cluster 을 이용하여 분산처리가 가능하도록 한다.
○ 구성요소
- 분산 모드 마스터 / 슬레이브 구조
- 중앙 조정자(드라이버) + 분산 작업 노드(익스큐터)

구성요소 - 드라이버 노드
- 사용자의 main 메소드가 실행되는 프로세스.
- 사용자 프로그램을 태스크로 변환하여 클러스터로 전송.
- 익스큐터에서의 개별 작업들을 위한 스케쥴링을 조정
작업 노드
- 개별 태스크를 실행하는 작업 실행 프로세스
- 태스크 실행 후 결과를 드라이버로 전송
- 사용자 프로그램에서 캐시하는 RDD를 저장하기 위한 메모리 공간 제공
클러스터 매니저
- 스파크는 익스큐터를 실행하기 위해 클러스터 매니저에 의존 (Standalone, Hadoop Yarn, Apache Mesos)
○ 프로그램이 실행되는 단계
1. 사용자가 spark-submit을 사용해 애플리케이션 제출
2. spark-submit은 드라이버 프로그램을 실행하여 main 메소드 호출
3. 드라이버는 클러스터 매니저에서 익스큐터 실행을 위한 리소스 요청
4. 클러스터 매니저는 익스큐터를 실행
5. 드라이버는 태스크 단위로 나누어 익스큐터에 전송
6. 익스큐터는 태스크를 실행
7. 애플리케이션이 종료되면 클러스터 매니저에게 리소스 반납
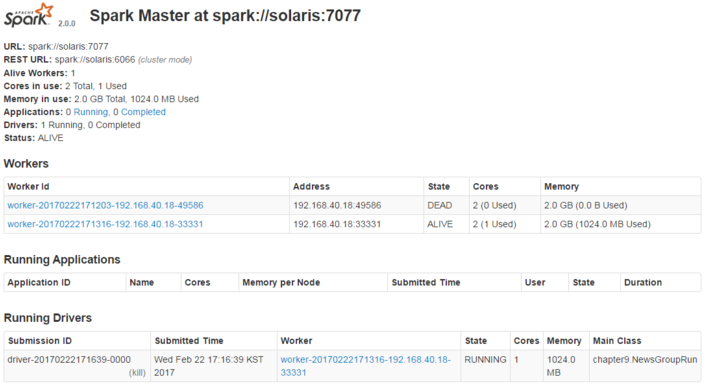
○ 테스트
1. master spark server 시작
./sbin/start-master.sh
ps -ef | grep spark
2. worker node 시작
./sbin/start-slave.sh spark://solaris:7077
./sbin/start-slave.sh spark://solaris:7077 --cores 2 --memory 4g
ps -ef | grep spark
3. 실행 소스 입력
실행 jar 파일 : JavaSpark-0.0.1.jar
./bin/spark-submit \
--master spark://hostname:7077 \
--deploy-mode cluster \
--class chapter9.NewsGroupRun \
--name "NewsGroupRun" \
--total-executor-cores 4 \
--executor-memory 1g \
./JavaSpark-0.0.1.jar
'공부 > Apache spark' 카테고리의 다른 글
| [Spark] 스파크 설치 & 기본실행 (0) | 2021.04.12 |
|---|---|
| [kaggle] Titanic: Machine Learning from Disaster (0) | 2021.03.10 |